by Anna-Lena Lamprecht, et al.
Data Science, Vol.3, Iss.1, pp. 37–59, 2020
Introduction
The FAIR Guiding Principles were published and promoted to improve the reuse of scholarly data by making it more findable, accessible, interoperable, and reusable by humans and machines. Implementing FAIR helps researchers demonstrate the impact of their work by enabling the reuse and citation of the data they produce, and can promote collaboration among them. It also helps publishers and funders to define policies for data sharing, and to promote discoverability and reuse. In addition, it helps data stewards and managers to provide guidance on quality criteria for data deposits in digital repositories.
The authors' intention was that the principles not only apply to data, but also to other digital objects, e.g. algorithms, tools, and workflows, that led to that data, as all these elements must be available to ensure transparency, reproducibility and reusability. At the policy level, software is indeed seen as part of FAIR, with the European Commission expert group on FAIR data stating that “Central to the realisation of FAIR are FAIR Digital Objects, which may represent data, software or other research resources.” Applying the FAIR principles in a useful way to research software will provide similar benefits of enabling transparency, reproducibility and reusability of research, making it easier for industry, science, education and society to have effective access to software-based knowledge. In particular, FAIR software should facilitate making FAIR data.
However, software is data and software is not data. Over the last three years, numerous discussions have taken place with the aim of understanding how the FAIR principles relate to software. It is clear that the four foundational principles are intended to apply to software, but can we apply them in a practical and useful way? The terminology and detail used in the 15 FAIR Guiding Principles is focused on their application to data – particularly in the life sciences – and can be confusing if applied to software without translation. The drivers, stakeholders and incentives, whilst overlapping, are not identical. In addition, the variety of software and its distribution channels poses a challenge when adapting the current FAIR principles.
FAIR principles applied to research software
We understand the original 15 FAIR Guiding Principles as an instantiation of the four foundational FAIR principles in the context of research data.
Findability
Findability is a fundamental principle, since it is necessary to find a resource before any other consideration. The main concern of findability for research software is to ensure software can be identified unambiguously when looking for it using common search strategies. Such strategies include the use of keywords in general-purpose search engines like Google, as well as specialised registries (websites hosting software metadata) and repositories (websites hosting software source code and binaries). Findability can be improved by registering the software in a relevant registry, along with the provision of appropriate metadata, providing contextual information about the software. Registries typically render metadata in a web-findable way and can provide a DOI. Some registries and repositories allow annotating software using domain-agnostic or domain-specific controlled vocabularies, increasing findability via search engines further. In the following we discuss how the original four Findability principles apply to the findability of research software.
Accessibility
In the original FAIR Guiding Principles, accessibility translates into retrievability through a standardized communication protocol and accessibility of metadata even when the original resource is no longer accessible. These principles clearly also apply to software. Interpreting accessibility also as the ability to actually use the software (access its functionality), however, we found mere retrievability not enough. In order for anyone to use any research software, a working version of the software needs to be available. This is different from just archiving source code, even in comprehensive and long-term collections like the Software Heritage archive. To use software, a working version (binary or code) has to be either downloadable and/or accessible e.g., via a web interface, along with the required documentation and licensing information. Accessibility requirements depend on the software type, e.g., web-applications, command-line tools, etc. For example, software containers allow the use across different operating systems and environments, e.g., local computers, remote servers, and high-performance computing (HPC) installations.
Cloud-based servers can execute existing pieces of code as a service, as software made available through a web interface or via Jupyter Notebooks. Notebooks allow others to see the results and the narrative alongside the code used to generate them.
Interoperability
When examining the FAIR data principles from a research software perspective, interoperability turns out to be the most challenging among the four high-level principles. This is not surprising given the complexity of the software interoperability challenges that form a research area of its own. Already for data and its associated metadata, interoperability has been found to be “the most challenging of the four FAIR principles. This, in part, is due to interoperability not being well understood.” In contrast to the rather static nature of data, research software are live digital objects that interact at different levels with other objects, e.g., other software, managed data, execution environments; and either directly and/or indirectly, as scripts or as part of a workflow (see Fig.1). The interoperability principles are therefore even more challenging to apply to software, some are not directly applicable, others need to be rephrased and even new principles need to be defined to appropriately address the dynamic nature of software.
Software interoperability can be defined from three different angles:
- for a set of independent but interoperable objects to produce a runnable version of the software, including libraries, software source code, APIs and data formats, and any other resources for facilitating that task;
- for a stack of digital objects that should work together for being able to execute a given task including the software itself, its dependencies, other indirect dependencies, the whole execution environment including runtime dependencies and the operating system, the execution environment, dependencies, and the software itself; and
- for workflows, which interconnect different standalone software tools for transforming one or more data sets into one or more output data sets through agreed protocols and standards.
Thus, interoperability for software can be considered both for individual objects, which are the final product of a digital stack, and as part of broader digital ecosystems, which includes complex processes and workflows as well as their interaction. Different pieces of software can also work together independent of programming languages, operating systems and specific hardware requirements through the use of APIs and/or other communication protocols.
Reusability
Reusability in the context of software has many dimensions. At its core, reusability aims for someone to be able to re-use software reproducibly. The context of this usage can vary and should cover different scenarios: (i) reproducing the same outputs reported by the research supported by the software, (ii) (re)using the code with data other than the test one provided to obtain compatible outputs, (iii) (re)using the software for additional cases other than those stated as supported, or (iv) extending the software in order to add to its functionality. Software reusability depends to a high degree on software maintainability, including proper documentation at various levels of detail. The legal framework, e.g., software licenses, is also important in terms of reusability as it determines how software can be built, modified, used, accessed and distributed. Furthermore, as research software is an integral part of the scientific process, credit attribution (citation) is another important aspect to consider with regard to (re)usability.
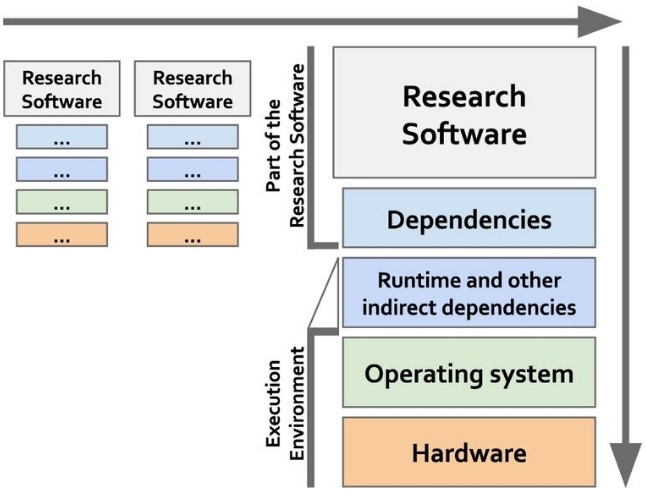
Fig.1 Interoperability for research software can be understood in two dimensions: as part of workflows (horizontal dimension) and as stack of digital objects that need to work together at compilation and execution times (vertical dimension). Importantly, workflows do not need to use the same physical hardware or the same operating system, as long as there are agreed mechanisms for software to interoperate with one another.